บทนำ
ข้อมูล เป็น สิ่งที่บ่งบอกถึงลักษณะปัจจุบันของกระบวนการและผลการดำเนินงานขององค์กร การวิเคราะห์ข้อมูลและการนำเอาข้อมูลมาใช้งานให้เกิดประโยชน์ที่สูงที่สุดนั้น จึงเป็นสิ่งหนึ่งที่องค์กรทั้งภาครัฐและเอกชนในปัจจุบันพยายามสร้างให้องค์กรมีศักยภาพในด้านการนำเอาข้อมูลมาใช้งาน ข้อมูลทั้งหลายเหล่านี้ถูกเก็บมาจากกระบวนการทางธุรกิจ และแสดงถึงสถานะปัจจุบันขององค์กร ยิ่งไปกว่านั้นการนำเอาข้อมูลมาประมวลผลในขั้นสูง อาจทำให้เราสามารถใช้ข้อมูลในการคาดเดาสิ่งที่อาจจะเกิดขึ้น และนำเอาไปประยุกต์และผนวกเข้ากับการดำเนินการขององค์กรได้ ทำให้องค์กรนั้นๆ มีศักยภาพและข้อได้เปรียบในการแข่งขัน เมื่อเทียบกับคู่แข่ง
สิ่งเหล่านี้เองทำให้เทคโนโลยีการประมวลผลข้อมูลขนาดใหญ่ (Big Data Analytics) เป็นที่สนใจในวงการทั้งภาครัฐและธุรกิจใน 3-5 ปีที่ผ่านมา ทั้งนี้คำว่าข้อมูลขนาดใหญ่หรือ Big Data ก็ถูกนำไปใช้ให้หมายถึงการที่องค์กรนำเอาข้อมูลที่มีอยู่แล้วมาใช้งาน ซึ่งก็มีความหมายที่คล้ายกับการวิเคราะห์ข้อมูลหรือ Data Analytics องค์การในส่วนธนาคาร บริษัทขนาดใหญ่ และภาครัฐ ต่างนำเอาเทคโนโลยีการประมวลผลข้อมูลขนาดใหญ่นี้ไปประยุกต์ใช้ในองค์กร อย่างไรก็ตามองค์กรดังกล่าวมักจะพบว่า ข้อมูลที่มีอยู่ในองค์กรนั้นในความเป็นจริงไม่ได้มีขนาดใหญ่ที่อาจจะจำเป็นที่จะต้องใช้การประมวลผลข้อมูลด้วยระบบคลัสเตอร์คอมพิวเตอร์ (Computer Cluster) แต่อาจต้องการเครื่องมือที่ช่วยให้สามารถประมวลผลข้อมูลบนเครื่องคอมพิวเตอร์ที่มีประสิทธิภาพสูงได้ กล่าวคือ การใช้งานระบบคลัสเตอร์นั้นเรามักจะมีคอมพิวเตอร์หลายๆ เครื่องที่กระจายการทำงาน ซึ่งแต่ละเครื่องอาจไม่จำเป็นต้องมีสมรรถนะที่สูงเท่าใด ในขณะที่เครื่องคอมพิวเตอร์ที่มีประสิทธิภาพสูงนั้นจะมีทั้งหน่วยประมวลผลกลาง (CPU) และหน่วยความจำที่มีปริมาณมาก ด้วยการเติบโตของเทคโนโลยีด้านฮาร์ดแวร์ทำให้ต้นทุนของการสร้างคอมพิวเตอร์ที่มีประสิทธิภาพสูงนั้นต่ำลง การประมวลข้อมูลขนาดใหญ่นั้น ยังต้องการแพลตฟอร์มระบบที่มีความเฉพาะเจาะจง สิ่งนี้เองก็เป็นอุปสรรคที่องค์กรจะต้องหาหรือพัฒนาบุคลากรที่มีความสามารถในการจัดการ และใช้งานระบบดังกล่าว
ในขณะเดียวการ การเตรียมข้อมูลบนเครื่องคอมพิวเตอร์เพื่อการประมวลผลในปัจจุบันมักจะใช้Pandas ซึ่งเป็น Library Package ในภาษา Python ที่ช่วยให้เราสามารถประมวลผลและเตรียมข้อมูลให้ได้ตามความต้องการของผู้ใช้ หรืออาจใช้ SQL ในการสั่งงานฐานข้อมูลให้จัดการเตรียมข้อมูลดังกล่าว อย่างไรก็ตาม Pandas นั้น โดยมากการประมวลผลจะทำงานด้วย CPU Core เพียงหนึ่งหน่วยเป็นหลัก ถึงแม้เครื่องคอมพิวเตอร์นั้นจะมี 16 CPU Core หรือ 32 Logical Processors การทำงานก็จะเน้นไปที่การใช้ CPUCore เพียงหน่วยเดียวเท่านั้น
จุดเด่นของ Polars
Polars (https://www.pola.rs/) เป็นหนึ่งใน Library ที่ถูกสร้างขึ้นมาเพื่อเพิ่มประสิทธิภาพในการประมวลผลข้อมูล ด้วยการสร้าง DataFrame API ที่สนับสนุนการประมวลผลข้อมูลแบบขนาน (Parallel Processing)และใช้งาน CPU Core อย่างเต็มที่ โดยที่วิธีการใช้งานนั้นยังมีลักษณะที่เหมือนกันกับ Pandas ซึ่งทำให้การทำงานงานของโปรแกรมทำได้เร็วมากยิ่งขึ้น และการเรียนรู้และการใช้งานนั้นทำได้ง่าย จุดเด่นของPolars นั้นได้แก่
- ประสิทธิภาพสูง: Polars เป็น DataFrame library ที่ทำให้การทำงานของ DataFrame นั้นมีประสิทธิภาพสูงด้วยการประมวลผลแบบขนาน นอกจากนี้ Polars ยังเป็น Library ที่ถูกพัฒนาด้วยภาษา Rust ที่มีจุดเด่นด้านประสิทธิภาพด้วย
- ใช้งานง่าย: Polars นั้นมีลักษณะการใช้งานที่คล้ายคลึงการ Pandas และ PySpark ทำให้การใช้งานทำได้ง่าย
- สนับสนุนการทำงานแบบ Lazy: Polars สนับสนุนการประมวลผลทั้งแบบ Eager และ Lazy processing ทำให้การสั่งการประมวลผลนั้นถูกปรับแต่งค่าให้ดีที่สุด (Query/Computational Optimization) โดยอัตโนมัติ
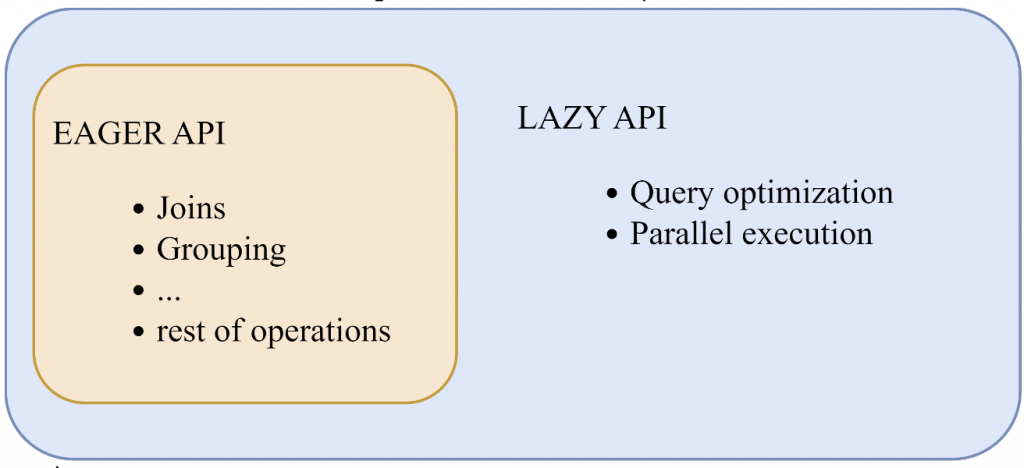
รูปที่ 1 แสดงลักษณะการทำงานแบบ Eager และ Lazy API ของ Polars (https://pola-rs.github.io/polars-book/user-guide/ )
เมื่อเปรียบเทียบกับ Dask
Dask เป็น Library Package ของ Python ที่สนับสนุนการประมวลผลแบบขนาน Dask ถูกพัฒนาเพื่อทำให้กระบวนการการประมวลผลของ Python นั้นสามารถทำงานได้โดยการแบ่ง Workload ของงาน Single Thread ที่ถูกพัฒนามาอยู่แล้ว ในขณะที่ Polars นั้นถูกพัฒนาโดยมุ่งเน้นในการทำให้การใช้งาน DataFrameนั้นประมวลผลแบบขนานโดยเฉพาะ ทั้ง Dask และ Polars ต่างก็มุ่งเน้นในการที่ทำให้การประมวลผลนั้นสามารถทำงานได้แบบขนาดทั้งคู่ ความแตกต่างจึงเป็นที่แนวทาง อัลกอริทึมและลักษณะโครงสร้างในการทำงานภายในของ Library ที่มีความแตกต่างกัน
เมื่อเปรียบเทียบกับ PySpark
PySpark เป็น Client Library บน Python ที่เชื่อมต่อกับ Spark ที่ทำงานอยู่บนระบบการประมวลผลข้อมูลขนาดใหญ่ แบบคลัสเตอร์คอมพิวเตอร์ PySpark มี DataFrame API ที่ทำให้การสร้างและประมวลผลDataFrame บน PySpark นั้นสามารถกระจายไปทำงานในเครื่องที่อยู่บนคลัสเตอร์แยกกันได้ ทำให้ข้อมูลขนาดใหญ่จะถูกประมวลผลด้วยเครื่องหลายๆ เครื่องพร้อมๆ กัน ในขณะที่ Polars นั้นเน้นในการทำงานแบบขนานบนเครื่องหนึ่งเครื่องที่มีทรัพยากรเพียงพอ แต่ต้องการประมวลผลข้อมูลให้มีประสิทธิภาพที่สูงขึ้น โดยไม่ต้องมีคลัสเตอร์ของคอมพิวเตอร์มาช่วยในการประมวลผล ซึ่งเป็นความแตกต่างตามลักษณะของระบบที่เป็น Distributed Memory vs Share Memory Computing หรือในลักษณะของ COW (Cluster of Workstation) vs SMP (Symmetric Multi-Processor)
ตัวอย่างการประมวลผลข้อมูลด้วย Polars เมื่อเปรียบเทียบกับ Pandas
รายละเอียดของการทดสอบ
ข้อมูล ข้อมูลการแพทย์ฉุกเฉินจากประเทศ Mexico ในช่วงปี 2018 ถึง 2022 ขนาดข้อมูลแบบไม่บีบอัด 11.43GB (https://www.kaggle.com/datasets/tavoglc/medical-emergencies-data-from-mexico )
เครื่องคอมพิวเตอร์ที่ใช้ประมวลผล
CPU: Ryzen 9 5950X 16-Core 4.00GHz
RAM: 128GB 3200MHz
HDD: Samsung SSD 970 EVO NVME M.2
รายละเอียด Library Version
- pandas 1.4.4
- polars 0.16.1
ตัวอย่างที่ 1 – Selection and Filtering
Pandas
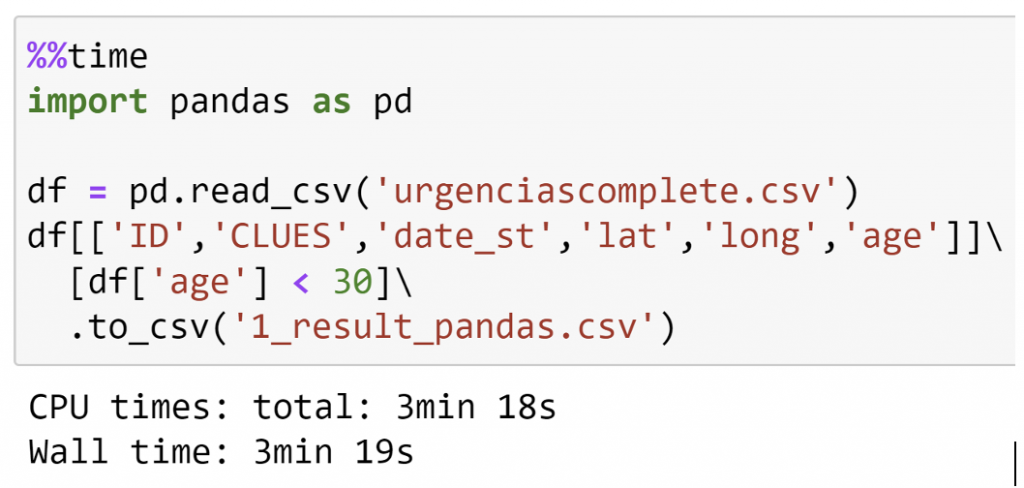
Polars

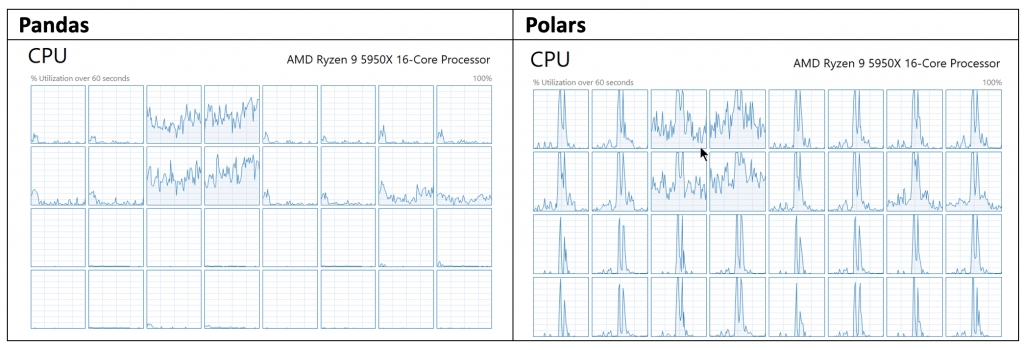
รูปที่ 2 CPU Utilization ของ Pandas และ Polars ของตัวอย่างที่ 1
ตัวอย่างที่ 2 – Aggregation
Pandas
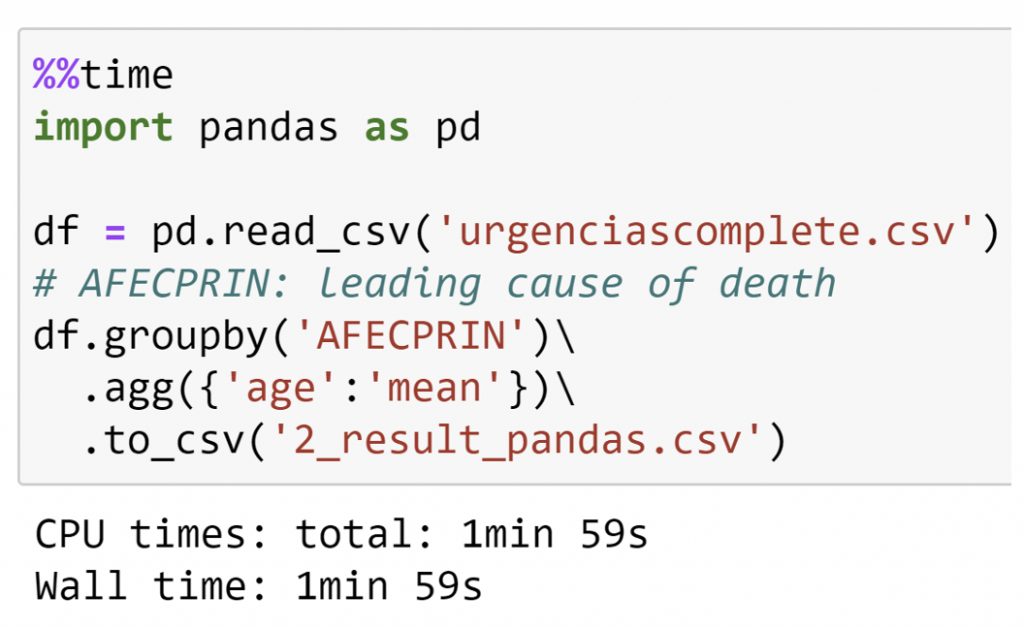
Polars

จากตัวอย่างข้างต้นพบว่า Polars นั้นมีประสิทธิภาพในการทำงานได้เร็วกว่า Pandas ถึง 20 เท่า หากพิจารณาที่ Wall time ในการทำงานของ Code ในขณะที่หากพิจารณา CPU times ก็จะพบว่า Polars นั้นใช้ CPU ได้คุ้มค่ากว่าการทำงานของ Pandas ซึ่งหากผนวกเอาการประมวลผลแบบ Lazy Evaluation เข้าไปเพิ่มเติมก็จะยิ่งเพิ่มประสิทธิภาพการประมวลผลนี้ได้ยิ่งขึ้นไปอีก
การพัฒนาเทคโนโลยีด้านการประมวลผลข้อมูลทำให้เราสามารถทำการเตรียม ประมวลผล จัดการ และวิเคราะห์ข้อมูลได้อย่างมีประสิทธิภาพ ซึ่งจะเพิ่มศักยภาพของกระแสข้อมูลให้สามารถทำงานได้อย่างมีประสิทธิภาพที่สูงขึ้น และเป็นตัวเลือกหนึ่งขององค์กรในการใช้งานเทคโนโลยีด้านวิศวกรรมข้อมูลเพื่อเสริมศักยภาพในการประมวลผลข้อมูลขององค์กรต่อไป
เขียนโดย ผศ.ดร.สันติธรรม พรหมอ่อน, 31 มกราคม 2566
Asst.Prof.Dr.Santitham Prom-on / January 31, 2023