ความผิดปกติในข้อมูลเป็นสิ่งที่หลายๆธุรกิจไม่ต้องการให้เกิดขึ้น การผิดปกติที่เกิดขึ้นเพียงเล็กน้อยอาจนำไปสู่การสูญเสียที่มหาศาลได้ ดังนั้นการตรวจพบความผิดปกติในระบบตั้งแต่เบื้องต้น จะเป็นการยับยั้งการสูญเสียที่บานปลายได้ในอนาคตนั่นเอง ยกตัวอย่างเช่น การรุกรานในระบบเครือข่าย (Network Intrusion) ที่อาจหมายถึงการสูญเสียข้อมูลความลับขององค์กร รวมไปถึงข้อมูลของลูกค้าที่ทำให้ความเชื่อมั่นในธุรกิจลดน้อยลงได้ ปัญหาเหล่านี้ควรถูกตรวจสอบ และแก้ไขปัญหาตั้งแต่เนิ่น ๆ ก่อนที่จะส่งผลกระทบในวงกว้าง และสร้างความเสียหายให้กับผู้ให้บริการได้ [1]
โดยทั่วไปข้อมูลผิดปกติจะเกิดขึ้นได้ยาก และพบเห็นไม่บ่อยนัก ซึ่งสร้างความท้าทายสำหรับนักวิจัย และนักวิทยาศาสตร์ข้อมูล (Data Scientist) เป็นอย่างมาก แม้ว่าปัจจุบันที่การเรียนรู้ของเครื่อง (Machine Learning) เป็นที่นิยมอย่างแพร่หลาย แต่วิธีการนี้ยังมีข้อจำกัดสำหรับการแยกความผิดปกติของข้อมูลเนื่องจากผลลัพธ์ที่ได้อาจมีปัญหา Overfit กับข้อมูลที่นำมาใช้เรียนรู้สำหรับโมเดล ทำให้เกิดข้อผิดพลาดเมื่อนำไปใช้กับข้อมูลในสถานการณ์จริงได้
วิธีการดั้งเดิมที่ยังคงได้ผลเสมอ นั่นคือวิธีการคำนวณเชิงสถิติ เนื่องจากผลลัพธ์ที่ได้เกิดจากการคำนวณโดยตรงจากข้อมูลที่เราสนใจ อีกทั้งวิธีการนี้ยังใช้จำนวนข้อมูลที่น้อยกว่าวิธี Machine Learning ที่ต้องอาศัยจำนวนข้อมูลมหาศาลเพื่อเรียนรู้จนถึงจุดที่ยอมรับได้ แต่วิธีการดั้งเดิมยังคงมีข้อจำกัดในเรื่องความซับซ้อนของปัญหาที่ไม่ควรจะซับซ้อนจนเกินไป ทั้งนี้ปัญหาความผิดปกติในข้อมูลมีความซับซ้อนที่น้อยมาก เพราะมีแค่ 2 ประเภท คือ ข้อมูลที่ผิดปกติ (Anomaly) และข้อมูลที่ปกติ (Normal) ดังนั้นบทความนี้จึงขอเสนอวิธีการหนึ่งที่ค่อนข้างง่าย และมีประสิทธิภาพ เรียกว่า Isolation Forest [2]
หลักการของ Isolation Forest มีรากฐานมาจาก Decision Tree โดยมีเป้าหมายคือการแบ่งข้อมูลไปเรื่อย ๆ จนกระทั่งข้อมูลนั้นไม่สามารถแบ่งให้เล็กกว่านี้ได้อีกแล้ว หรือก็คือแบ่งจนกว่าข้อมูลแต่ละตัวจะแยกจากกันโดยสมบูรณ์นั่นเอง
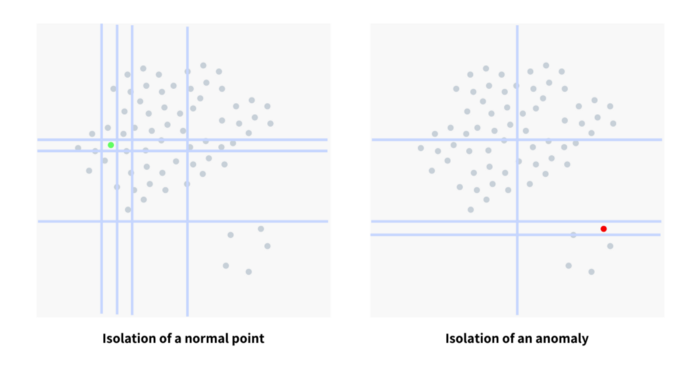
ยกตัวอย่างง่ายๆ ถ้าสมมติว่ามีข้อมูลเป็นจุดสีเทากระจายตัวในลักษณะดังรูปที่ 1 หากเราต้องการจะแบ่งข้อมูลออกจากกันก็แค่สร้างเส้นแบ่งขึ้นมา อาจจะเป็นแนวตั้งหรือแนวนอนก็ได้ แต่ว่าต้องแบ่งจนกว่าจุดที่เราสนใจจะถูกแยกออกจากจุดอื่นโดยสิ้นเชิง ซึ่งพิจารณารูปทางซ้ายจะเห็นได้ว่าข้อมูลปกติจะอยู่กระจุกตัวกับข้อมูลจุดอื่นๆ ทำให้ต้องใช้จำนวนเส้นในการแบ่งค่อนข้างมาก เปรียบเทียบกับข้อมูลผิดปกติรูปทางขวาที่จะอยู่แยกจากข้อมูลส่วนใหญ่ ทำให้ใช้จำนวนเส้นแบ่งที่น้อยกว่าก็สามารถแยกออกมาได้แล้ว
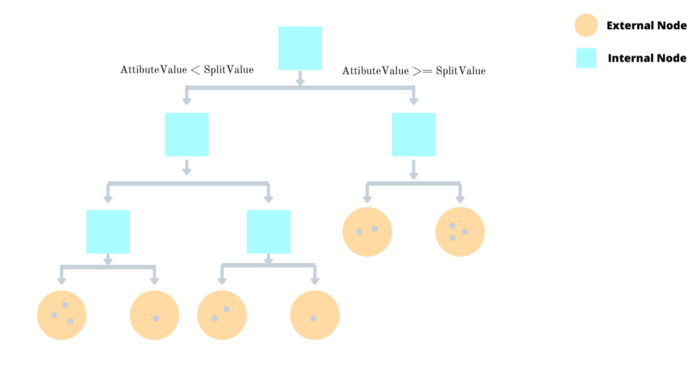
ด้วยหลักการข้างต้น ถ้าเรามองเป็นต้นไม้ตัดสินใจ (Decision Tree) จะได้ว่าเส้นแบ่งแต่ละเส้นก็คือเส้นที่ตัดแบ่งข้อมูลทั้งหมดออกเป็นกิ่งซ้าย และกิ่งขวา แล้วทำการแบ่งไปจนกระทั่งถึงจุดที่ทุกอย่างแยกออกจากกัน ทำให้เราจะได้ต้นไม้ที่มีกิ่งแยกข้อมูลออกจากกัน หลังจากนั้นถ้าสังเกตดีๆจะพบว่าเราสามารถแยกข้อมูลผิดปกติออกจากข้อมูลปกติได้แล้วด้วย “ความลึก” ของต้นไม้ เนื่องจากข้อมูลปกติจะใช้จำนวนชั้นของต้นไม้ที่ลึกมากในการแบ่งข้อมูลให้เป็นอิสระจากกัน แต่ข้อมูลผิดปกติจะถูกกรองตั้งแต่ชั้นแรกๆของต้นไม้แล้ว ทำให้ความลึกของข้อมูลที่ผิดปกติจะตื้นกว่าข้อมูลอื่นๆ
เมื่อทราบความลึกของต้นไม้แล้วเราสามารถคำนวณเป็นคะแนนความผิดปกติ (Anomaly score) เพื่อใช้ในการแยกประเภทของข้อมูลได้ ซึ่งคะแนนความความผิดปกตินั้นจะมีค่าตั้งแต่ 0 ถึง 1 โดยค่าที่เข้าใกล้ 1 จะหมายถึงข้อมูลที่มีแนวโน้มผิดปกติ ส่วนข้อมูลที่มีค่าน้อยกว่า 0.5 ลงไปจะถือว่าเป็นข้อมูลทั่วไปที่ไม่มีความผิดปกติ เพียงเท่านี้เราก็สามารถแยกข้อมูลผิดปกติด้วย Isolation Forest ได้แล้ว
จะเห็นได้ว่าวิธีที่กล่าวมาใช้คณิตศาสตร์แบบพื้นฐานมากๆ ทำให้เวลาที่ใช้ในการประมวลผลค่อนข้างรวดเร็ว เนื่องจากมีความซับซ้อนที่น้อยกว่า จึงสามารถนำไปประยุกต์ใช้กับปัญหาทั่วไปๆเกือบทุกปัญหาบนโลกได้ โดยบทความนี้ได้ยกตัวอย่างมา 2 ปัญหาด้วยกัน ดังนี้
การตรวจสอบการโกงบนบัตรเครดิต (Credit Card Transaction Anomaly Detection)
ปัญหาแรกค่อนข้างเป็นที่นิยมคือการโกงบัตรเครดิต เนื่องจากปัจจุบันมีการทำธุรกรรมออนไลน์เป็นจำนวนมาก รายการเดินบัญชีมีมากมายมหาศาลนับไม่ถ้วน การโกงหนึ่งครั้งอาจลามไปสู่การชดเชยค่าเสียหายทางธุรกิจนับหลายล้านบาทได้ อีกทั้งการจะมานั่งเฝ้าระวังคอยดูรายการเดินบัญชีวันละหลายๆล้านบรรทัดก็คงจะไม่ใช่ทางออกที่ดีนัก Isolation forest จึงเข้ามาแก้ไขปัญหาได้เป็นอย่างดี เพราะต้องการข้อมูลเพียงแค่ยอดค่าใช้จ่ายในแต่ละรายการเดินบัญชีก็สามารถดูแนวโน้มที่ผิดปกติ และสามารถแสดงออกมาได้อย่างง่ายดาย
โดยจากผลการวิจัย [3] แสดงให้เห็นถึงประสิทธิภาพของ Isolation forest ที่ให้ความแม่นยำมากถึง 95% และเหนือกว่าวิธีแบบเดิม ๆ อย่าง SVM และ K-mean อีกด้วย
การตรวจสอบข้อมูลบันทึกที่ผิดปกติ (Log Anomaly Detection)
ปัญหาถัดมาเป็นเรื่องที่มีความซับซ้อนขึ้นเนื่องจากข้อมูลที่เข้ามาไม่ได้เป็นเพียงตัวเลขแล้ว แต่เป็นข้อความบันทึกจากเครื่องคอมพิวเตอร์ หรือเครื่องผู้ให้บริการ (Server) ที่เกิดขึ้นในระบบ การนำ Isolation forest มาประยุกต์ใช้นั้น สามารถทำได้โดยการแปลงข้อมูลบันทึกที่อยู่ในรูปแบบของข้อความ (Text) ให้อยู่ในรูปแบบของตัวเลข (Numeric) ได้ ด้วยการนับจำนวนความถี่ของการเกิดคำนั้นๆในบรรทัด เราจะเห็นได้ว่าความถี่ของคำบางคำที่น้อยกว่าปกติ อาจหมายถึงเหตุการณ์ผิดปกติที่เกิดขึ้นไม่บ่อยนักได้ ทำให้เราสามารถใช้ Isolation forest ในการแยกความผิดปกติของข้อมูลบันทึกที่อยู่ในรูปแบบข้อความได้
จากผลการวิจัย [4] ยิ่งแสดงให้เห็นถึงประสิทธิภาพของ Isolation forest เมื่อเทียบกับวิธีการอื่นๆ โดย Isolation forest มีความถูกต้องที่มากกว่าด้วยเวลาในการประมวลผลที่เท่าเดิม และอาจจะรวดเร็วกว่าในบางอัลกอลิทึม
สุดท้ายนี้ Isolation forest สามารถทำให้การตรวจสอบความผิดปกติในงานต่างๆเป็นเรื่องที่ง่ายขึ้น ซึ่งใช้เวลาในการประมวลผลค่อนข้างน้อย อีกทั้งยังให้ผลลัพธ์ที่แม่นยำในระดับที่ยอมรับได้ แม้ว่ามีข้อจำกัดบางอย่าง เช่น ไม่สามารถใช้กับข้อมูลที่ไม่ใช่ตัวเลข เป็นต้น แต่ก็สามารถประยุกต์ใช้วิธีนี้ได้ ถ้าหากหาความเชื่อมโยงระหว่างข้อมูลชนิดนั้นๆกับตัวเลขได้ ตัวอย่างเช่นความถี่ของคำที่ได้กล่าวไว้ในปัญหาการตรวจสอบข้อมูลบันทึก นอกจากนี้ Isolation forest ยังขาดการพัฒนาเพื่อใช้งานแบบเรียลไทม์ เนื่องจากปัจจุบันมีการใช้งานอัลกอทึมเพียงแบบออฟไลน์โดยนำข้อมูลเก่าที่ไม่มีการเคลื่อนไหวมาใช้เพื่อวิเคราะห์ผลลัพธ์ในอดีต ในขณะที่ปัจจุบันข้อมูลมีการเปลี่ยนแปลงตลอดเวลา การวิเคราะห์ผลลัพธ์แบบเรียลไทม์จึงเป็นสิ่งสำคัญที่จะทำให้ระบบมีการพัฒนาก้าวหน้ามากยิ่งขึ้น แต่อย่างไรก็ดีหากมีการประยุกต์ใช้อัลกอริทึมนี้อย่างแพร่หลายมากขึ้นอาจส่งผลให้มีการพัฒนาให้สามารถใช้งานแบบเรียลไทม์ได้ตามมาในที่สุด
References
[1] P.-F. Marteau, S. Soheily-Khah and N. Béchet, “Hybrid Isolation Forest – Application to Intrusion Detection,” arXiv e-prints , 2017.
[2] F. T. Liu, K. M. Ting and Z.-H. Zhou, “Isolation Forest,” IEEE International Conference on Data Mining, pp. 413-422, 2009.
[3] S. Ounacer, H. A. E. Bour, Y. Oubrahim, M. Y. Ghoumari and M. Azzouazi, “Using Isolation Forest in anomaly detection: the case of credit card,” Periodicals of Engineering and Natural Sciences, vol. 6, no. 2, pp. 394-400, 2018.
[4] A. Farzad and T. A. Gulliver, “Unsupervised log message anomaly detection,” ICT Express, vol. 6, no. 3, pp. 229-237, 2020.
By: Arnatchai Techaviseschai (Art)